VQA - 近五年视觉问答顶会论文创新点笔记
简要梳理近五年顶级会议发表的视觉问答(Visual Question Answering, VQA)相关论文的创新点。选取自NIPS、CVPR、ICCV、ACL等,已整理86篇。
2019.10.21修订,新增5篇ACL 2019。
VQA - 近五年视觉问答顶会论文创新点笔记
2014 A Multi-World Approach to Question Answering about Real-World Scenes based on Uncertain Input
Malinowski M, Fritz M. A multi-world approach to question answering about real-world scenes based on uncertain input[C]//Advances in neural information processing systems. 2014: 1682-1690.
本文是VQA的概念萌芽作,但此后的文章【2015 VQA Visual Question Answering】认为本文定义的问题把answers限制在了预定义的16种基础颜色和894种目标类别中,只算VQA Efforts,没有真正定义VQA。

本文在一个贝叶斯框架中,把对真实世界场景的语义分割和对问题语句的符号推理结合起来,实现自动问答。
本文给出了一个含1.2万条人工标注问答对的RGBD彩色景深图像数据集。
2015 Are You Talking to a Machine Dataset and Methods for Multilingual Image Question
Gao H, Mao J, Zhou J, et al. Are you talking to a machine? dataset and methods for multilingual image question[C]//Advances in neural information processing systems. 2015: 2296-2304.
本文提出mQA模型,能够回答有关某个图像内容的问题。回答的答案可以是一个句子、短语或单词。
 to the model. The model is trained to generate the answer to the question (i.e. “Sitting on the umbrella”). The weight matrix in the word embedding layers of the two LSTMs (one for the question and one for the answer) are shared. In addition, as in [25], this weight matrix is also shared, in a transposed manner, with the weight matrix in the Softmax layer. Different colors in the figure represent different components of the model. (Best viewed in color.)")
本文模型含四部分:
- LSTM提取问题表示;
- CNN提取图像视觉表示;
- LSTM存储一个回答的语言上下文;
- 一个融合组件用于结合前三者并生成答案。
本文提供了一个自由风格多语种图像问答数据集(Freestyle Multilingual Image Question Answering, FM-IQA)。
2015 Ask Your Neurons A Neural-Based Approach to Answering Questions About Images
Malinowski M, Rohrbach M, Fritz M. Ask your neurons: A neural-based approach to answering questions about images[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1-9.
本文提出Neural-Image-QA模型。原理是encoder-decoder框架,把VQA建模为生成问题,在逐词编码完question句子后,逐词解码输出answer,以预测出<END>为结束符。
. To answer a question about an image, we feed in both, the image (CNN features) and the question (green boxes) into the LSTM. After the (variable length) question is encoded, we generate the answers (multiple words, orange boxes). During the answer generation phase the previously predicted answers are fed into the LSTM until the END symbol is predicted.")
2015 Exploring Models and Data for Image Question Answering
Ren M, Kiros R, Zemel R. Exploring models and data for image question answering[C]//Advances in neural information processing systems. 2015: 2953-2961.
本文提出使用神经网络、视觉语义嵌入来预测简单视觉问题的答案,而不加入中间步骤,比如:目标检测、图像分割。

也是一个类似encoder-decoder framework的东西,把图像特征和问题句子的各单词以此输入LSTM中进行编码,但没有解码输出句子,而是把编码完成时的向量用来在预定义词汇上做分类,预测答案单词。
本文还给出了一种问题生成算法,能够把图像描述转换为问题语句。
2015 Visalogy Answering Visual Analogy Questions
Sadeghi F, Zitnick C L, Farhadi A. Visalogy: Answering visual analogy questions[C]//Advances in Neural Information Processing Systems. 2015: 1882-1890.
本文研究视觉类比(Visual Analogy)问题。图像A对图像B,正如图像C和那个图像?
本文使用四路暹罗架构(quadruple Siamese architecture)的卷积神经网络。
 and (I3; I4) of correct analogies close to each other in the embedding space while forcing the distance between (I1; I2) and (I3; I4) in negative samples to be more than margin m.")
本文的Visalogy网络建立了共享θ参数的四路暹罗架构
2015 VisKE Visual Knowledge Extraction and Question Answering by Visual Verification of Relation Phrases
Sadeghi F, Kumar Divvala S K, Farhadi A. Viske: Visual knowledge extraction and question answering by visual verification of relation phrases[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 1456-1464.
本文主要关注视觉知识抽取,VQA是视觉知识抽取后的应用展示。
已有的知识抽取研究一般仅仅关注于通过文本驱动的推理来验证关系短语。(无法利用视觉)
本文首次提出对关系短语的视觉验证的研究问题,并开发了视觉知识抽取系统VisKE(Visual Knowledge Extraction system)
 VisKE formulates visual verification as the problem of estimating the most probable explanation (MPE) by searching for visual consistencies among the patterns of subject, object and the action being involved.")
输入的关系谓词:熊(noun, subjective) 捕鱼(verb) 鲑鱼(salmon, objective)。给定一个关系谓词,如:熊捕鱼,VisKE把视觉验证建模为对最可能解释(most probable explanation, MPE)的估计问题,通过搜素主语、宾语和动作三者模式之间的视觉一致性(visual consistencies)实现。
2015 Visual Madlibs Fill in the Blank Description Generation and Question Answering
Yu L, Park E, Berg A C, et al. Visual madlibs: Fill in the blank description generation and question answering[C]//Proceedings of the ieee international conference on computer vision. 2015: 2461-2469.
本文发布Visual Madlibs数据集,通过填空模板生成对人物、目标、外表、活动、互动、场景的描述。
2015 VQA Visual Question Answering
Antol S, Agrawal A, Lu J, et al. Vqa: Visual question answering[C]//Proceedings of the IEEE international conference on computer vision. 2015: 2425-2433.
本文首次提出VQA视觉问答任务。

2016 Answer-Type Prediction for Visual Question Answering
Kafle K, Kanan C. Answer-type prediction for visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4976-4984.
本文的核心思想是预测根据问题语句预测问题类型,用于VQA。

通过预测问题类型,选择针对该问题类型的模型进行VQA回答预测,提高VQA水平。
本文设计了一款贝叶斯模型。在图像特征x和问题特征q为的条件下,回答k且问题类型为c的概率。
2016 Ask Me Anything Free-Form Visual Question Answering Based on Knowledge from External Sources
Wu Q, Wang P, Shen C, et al. Ask me anything: Free-form visual question answering based on knowledge from external sources[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4622-4630.
本文研究视觉问答,通过把图像内容和外部知识库的信息结合起来,回答宽范围的基于图像的问题。
本文实际上是把图像信息转换为了属性词和文本描述,转换为了一般的问答问题解决。
. The internal textual representation is made up of image captions generated based on the image-attributes. The hidden state of the caption-LSTM after it has generated the last word in each caption is used as its vector representation. These vectors are then aggregated as Vcap(I) with average-pooling. The external knowledge is mined from the KB (in this case DBpedia) and the responses encoded by Doc2Vec, which produces a vector Vknow(I). The 3 vectorsV are combined into a single representation of scene content, which is input to the VQA LSTM model which interprets the question and generates an answer.")
通过image captioning把图像转文本,并向量化为\(V_{cap}\);通过image annotation把图像转单词属性\(V_{att}\),检索知识图谱获取文本描述,并向量化为\(V_{know}\);然后把以上\(V_{cap}\), \(V_{att}\), \(V_{know}\)向量都输入到LSTM解码器中,以query句为逐个step输入来输出回答句。
2016 Hierarchical Question-Image Co-Attention for Visual Question Answering
Lu J, Yang J, Batra D, et al. Hierarchical question-image co-attention for visual question answering[C]//Advances In Neural Information Processing Systems. 2016: 289-297.
本文提出不仅要建模视觉注意力(看什么位置),还需要建模问题注意力(关注哪些单词)。本文提出VQA协同注意力(Co-Attention)模型,可以对图像、问题注意力联合推理。
本文的Co-Attention指的是用图像表示来导向问题注意力,用问题表示来导向图像注意力。Co-Attention既能够关注图像中的不同区域,又能够关注问题中的不同块(单词、短语)
本文对问题文本构建了层次注意力机制(word level, phrase level, question level)。

本文把抽取问题的单词级、短语级和问题整句级嵌入。(对问题文本构建了层次注意力机制)。在每一级都通过co-attention机制来计算图像和问题的注意力。最后基于所有特征预测答案。
2016 Image Question Answering Using Convolutional Neural Network With Dynamic Parameter Prediction
Noh H, Hongsuck Seo P, Han B. Image question answering using convolutional neural network with dynamic parameter prediction[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 30-38.
本文认为,不同的问题,其问题类型、对输入图像的理解层次是不同的。(因此认为CNN要能够根据问题进行动态变化去适应问题需求)。
本文模型是一个具有动态参数层的CNN,动态参数层的权值能够适应性地由问题语句而定。
为实现适应性参数预测,本文设计了一个独立的参数预测网络,该网络通过GRU处理输入的问题语句,并通过全连接层来生成一组候选权值作为输出。
为CNN的全连接层生成大量参数很复杂,本文通过哈希技术来降低复杂性,利用哈希来计算参数预测网络的候选权值一并做出选择。
本文提出动态参数预测网络(DPPnet)。
, which is composed of the classification network and the parameter prediction network. The weights in the dynamic parameter layer are mapped by a hashing trick from the candidate weights obtained from the parameter prediction network.")
分类网络中的动态参数层的参数,是通过对参数预测网络的候选权值输出做哈希映射取得的。(因为让参数预测网络直接预测全连接层的大量参数太复杂了)
2016 MovieQA Understanding Stories in Movies Through Question-Answering
Tapaswi M, Zhu Y, Stiefelhagen R, et al. Movieqa: Understanding stories in movies through question-answering[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 4631-4640.
本文发布MovieQA数据集。

MovieQA数据集是多选题QA,让模型在5个选项中选答案。
其中有一个DVS的概念,DVS在对话之间插入的对电影场景的描述,是一项面向视障人士的服务。本文借助该服务取得文本描述。
本文参考了MemN2N模型设计了本文面向QA的Memory Network。
2016 Stacked Attention Networks for Image Question Answering
Yang Z, He X, Gao J, et al. Stacked attention networks for image question answering[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 21-29.
本文提出栈式注意力网络(stacked attention networks, SANs)。
SANs模型把问题语句表示为语义表示(向量),以此为查询来搜索图像中与答案相关的区域。本文认为VQA需要多步推理,因此设计了一个多层SAN,可以对图像做多次查询,以便渐进地推理出答案。
 Visualization of the learned multiple attention layers. The stacked attention network first focuses on all referred concepts, e.g., and objects in the basket (dogs) in bicycle, basket the first attention layer and then further narrows down the focus in the second layer and finds out the answer dog.")
结合可视化效果来看,多个注意力层实现的是缩小注意力范围的作用。
所谓的多步推理,其实就是先通过注意力机制找出问题中提及的图像内容,然后再逐步通过注意力在上一步找出的图像内容中进一步找注意区域。几步下来,注意力区域不断缩小,直至最值得注意的区域,即答案。
具体地,本文把VGGNet的最后一个池化层的结果取出来,得到512×14×14的,保持了原图空间信息矩阵。该矩阵把原图的空间划分为了14×14的网格区域,而每个区域通过一个512维的特征向量作为该区域的表示向量。并以此与问题特征向量计算每个区域的注意力权值。
14×14 is the number of regions in the image and 512 is the dimension of the feature vector for each region.
本文作者Zichao Yang、Xiaodong He等人恰好是Hierarchical Attention Network, HAN的提出者。我很喜欢他们的论文,对阐明原理非常负责任,总是能用最清晰的思路、最准确的表达来把技术原理讲得清清楚楚。在此致谢!
2016 Visual Question Answering with Question Representation Update (QRU)
Li R, Jia J. Visual question answering with question representation update (qru)[C]//Advances in Neural Information Processing Systems. 2016: 4655-4663.
本文指出要根据图像更新问题表示。 本文的方法是,对每一个图像区域进行迭代,每次迭代计算该图像区域与问题的相关性,选出与问题相关的图像区域来对问题表示(question representation)进行更新,并进一步学习给出正确答案,
.jpg "Figure 2: The overall architecture of our model with single reasoning layer for VQA")
问题Query0向量和M个图像区域的\(Query_{1 \sim M}\)向量计算取得M个\(Query^{1}_{1 \sim M}\)向量,由此根据图像的M个区域更新问题表示,即本文的问题表示更新QRU的概念。
2016 Visual7W Grounded Question Answering in Images
Zhu Y, Groth O, Bernstein M, et al. Visual7w: Grounded question answering in images[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 4995-5004.
先前的研究工作建立的是QA句子与图像之间的松散的、全局的关联,而本文的研究工作是建立图像中目标级的图像区域与文本描述的语义关联。
本文发布了Visual7W数据集,包含7万条多选题QA对。
本文的grounding指的是定位出图像中回答问题时依赖的目标

Visual7W数据集不仅包含图像、问题及其答案,还标注了答案对应的图像grounding区域。
2016 Where to Look Focus Regions for Visual Question Answering
Shih K J, Singh S, Hoiem D. Where to look: Focus regions for visual question answering[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 4613-4621.
本文提出的模型根据查询文本与图像区域之间的相关性来回答视觉问题。
本文认为模型要能学会根据问题去看图像中的什么地方。
通过内积计算相关性(查询文本和视觉特征之间)

图像区域特征向量 + 文本特征向量 // 此处“+”是连接
对每个区域的注意力权重,用于对右侧绿色框中的N个向量做加权平均。
dot product, softmax是一次注意力机制,根据文本特征关注图像区域。region向量和text向量映射到公共向量空间中。
2016 Yin and Yang Balancing and Answering Binary Visual Questions
Zhang P, Goyal Y, Summers-Stay D, et al. Yin and yang: Balancing and answering binary visual questions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 5014-5022.
本文关注于抽象场景中的二元VQA。
本文将二元VQA建模为视觉验证问题来解决,验证图像中是否存在问题中询问的概念。
, we use abstract scenes to collect a balanced dataset containing pairs of complementary scenes: the two scenes have opposite answers to the same question, while being visually as similar as possible. We view the task of answering binary questions as a visual verification task: we convert the question into a tuple that concisely summarizes the visual concept, which if present, result in the answer of the question being “yes”, and otherwise “no”. Our approach attends to relevant portions of the image when verifying the presence of the visual concept.")
本文一个问题配备两个互补的抽象场景,即一个对应yes,一个对应no。
本文实验使用的模型基于VQA方法。
2017 A Dataset and Exploration of Models for Understanding Video Data Through Fill-In-The-Blank Question-Answering
Maharaj T, Ballas N, Rohrbach A, et al. A dataset and exploration of models for understanding video data through fill-in-the-blank question-answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 6884-6893.
本文认为视频理解领域缺乏充足的数据。
本文给出MovieFIB(Movie Fill-In-the-Blank)数据集,含30万个样本,基于为视障人士准备的描述性视频注释。
MovieFIB采用填空(Fill-In-the-Blank)QA题型。
2017 An Analysis of Visual Question Answering Algorithms
Kafle K, Kanan C. An analysis of visual question answering algorithms[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1965-1973.
本文主要是给出一个新数据集——任务驱动图像理解挑战(Task Driven Image Understanding Challenge, TDIUC),包含的问题分类12个问题类别。 本文使用这个数据集分析现有的VQA算法。

另外,本文还加入了absurd问题,训练模型识别没道理、不相干的问题。
2017 An Empirical Evaluation of Visual Question Answering for Novel Objects
Ramakrishnan S K, Pal A, Sharma G, et al. An empirical evaluation of visual question answering for novel objects[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 4392-4401.
本文研究如何让VQA认知新目标。(训练集中没有的东西)。现有的热门VQA方法在遇到新目标时准确率大幅下挫。

使用外部语料和图片数据: 1. 无标签文本 2. 有标签图片
2017 Are You Smarter Than a Sixth Grader Textbook Question Answering for Multimodal Machine Comprehension
Kembhavi A, Seo M, Schwenk D, et al. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 4999-5007.
本文研究的教科书问答问题属于多模态机器理解(Multi-Modal Machine Comprehension, M3C):给定一个文本、流程图和图像组成的上下文,让机器能够回答多模态问题。
 paradigm, statistics of the proposed Textbook Question Answering (TQA) dataset and an illustration of a lesson in it. TQA can be downloaded at http://textbookqa.org .")
本文发布教科书问答(Textbook Question Answering, TQA)数据集。
本文的TQA数据集相较于现有的机器阅读理解和VQA研究更有难度,数据集中相当一部分的问题需要对文本、流程图进行复杂的解析和推理。
2017 Creativity Generating Diverse Questions Using Variational Autoencoders
Jain U, Zhang Z, Schwing A G. Creativity: Generating diverse questions using variational autoencoders[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 6485-6494.

本文提出结合变分自编码器(variational autoencoder, VAE)和LSTM来构建一个有创造力的算法,用于解决视觉问题生成问题。
2017 End-To-End Concept Word Detection for Video Captioning, Retrieval, and Question Answering
Yu Y, Ko H, Choi J, et al. End-to-end concept word detection for video captioning, retrieval, and question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3165-3173.
本文提出一个高层概念词检测器,能够整合到各种视频转语言的模型中。 该检测器根据输入的视频,生成一列概念词(concept words),提供给语言生成模型。

本文的概念词检测器(concept word detector),输入是视频及其对应的描述语句,训练后能够对每个视频生成一组高层概念词。
, and our video description model in bottom, which uses semantic attention on the detected concept words (section 3.1).")
加入了概念词检测器的encoder-decoder框架。
2017 Explicit Knowledge-based Reasoning for Visual Question Answering
Wang P, Wu Q, Shen C, et al. Explicit knowledge-based reasoning for visual question answering[C]//Proceedings of the 26th International Joint Conference on Artificial Intelligence. AAAI Press, 2017: 1290-1296.
本文提出的VQA模型能够基于从大型知识库中抽取的信息对图像进行推理。

本文的方法不仅能回答图像语义以外的问题,还能对推理取得答案的过程进行解释。
 is linked to DBpedia (right side) by mapping object/attribute/scene to DBpedia entities using the predicate same-concept. Bottom: The question processing pipeline. The input question is parsed using a set of NLP tools to identify the appropriate template. The extracted slot-phrases are then mapped to entities in the KB. Next, KB queries are generated to mine the relevant relationships for the KB-entities. Finally, the answer and reason are generated based on the query results. The predicate category/?broader is used to obtain the categories transitively.")
构建RDF图(Resource Description Framework [Cyganiak et al., 2014] (RDF)),拓展知识库,对自然语言进行解析、映射和逻辑查询取得推理过程可解释的答案。
2017 Graph-Structured Representations for Visual Question Answering
Teney D, Liu L, van den Hengel A. Graph-structured representations for visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1-9.
本文首次提出用图结构表示图像和问题文本,并建立深度学习模型进行处理实现分类。
本文: 1. 将图片编码为场景图; 2. 把句子表示为句法依存图; 3. 训练一个神经网络对场景图和依存图进行推理,并把结果分类为词汇中的一个词。
 and a parsed question (words with their syntactic relations). The scene-graph contains a node with a feature vector for each object, and edge features that represent their spatial relationships. The question-graph reflects the parse tree of the question, with a word embedding for each node, and a vector embedding of types of syntactic dependencies for edges. A recurrent unit (GRU) is associated with each node of both graphs. Over multiple iterations, the GRU updates a representation of each node that integrates context from its neighbours within the graph. Features of all objects and all words are combined (concatenated) pairwise, and they are weighted with a form of attention. That effectively matches elements between the question and the scene. The weighted sum of features is passed through a final classifier that predicts scores over a fixed set of candidate answers.")
要点: 1. 场景图(scene-graph):一组目标即其视觉特点。具体地,每一个目标对应一个节点。该节点包含一个特征向量;节点之间的边表示他们的空间关系。 2. 问题图(question-graph):句法解析后的问题语句。问题图是问题语句的解析树,每个单词对应一个节点。节点包含该单词的词嵌入(word embedding),节点之间的边包含单词之间句法依存关系的向量嵌入。 3. 所有目标和单词的特征向量两两成对组合组合起来,即图2中的Words-Objects矩阵,并通过注意力机制加权求和(Matching weights矩阵为注意力权重矩阵)。
局限:本文的scene graph只是包含空间上的相对位置(relative position)。
2017 High-Order Attention Models for Visual Question Answering
Schwartz I, Schwing A, Hazan T. High-order attention models for visual question answering[C]//Advances in Neural Information Processing Systems. 2017: 3664-3674.
本文提出一种注意力机制的新形式,能够学习不同数据模态之间的高阶相关性。
针对以往的注意力机制存在对特定任务手工设计因此针对性强、泛化性差的缺点,本文强调:
- 泛化性好(generally applicable),能够广泛应用于各种任务的注意力机制。
- 高阶相关性(high-order correlation),能够学习不同数据模态之间的高阶相关性。k阶相关性能够建模k种模态之间的相关性。
本文把目前的决策系统整体分解为三部分:
- 数据嵌入;
- 注意力机制;
- 决策产生;

本文把注意力机制视为概率模型,注意力机制计算“势”(potentials)。
- 一元势(unary potentials):\(\theta_V\)、\(\theta_Q\)、\(\theta_A\),表示视觉输入、问题语句、回答语句中每个元素的重要性。
- 成对势(pairwise potentials):\(\theta_{V,Q}\)、\(\theta_{V,A}\)、\(\theta_{Q,A}\)表示两种模态之间的相关性。
- 三元势(ternary potentials):\(\theta_{V,Q,A}\)捕捉三种模特之间的依存性。
本文的决策产生(decision making)阶段使用MCB和MCT池化:
- MCB池化(Multimodal Compact Bilinear Pooling):本文的决策生成阶段使用该双线性池化把成对情况(pairwise setting)下的两种模态做池化输出。
- MCT池化(Multimodal Compact Trilinear Pooling):本文的决策生成阶段使用该三线性池化把三种模态的数据池化输出。
2017 Knowledge Acquisition for Visual Question Answering via Iterative Querying
Zhu Y, Lim J J, Fei-Fei L. Knowledge acquisition for visual question answering via iterative querying[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1154-1163.
当人无法直接回答一个问题时,人会通过问一些补充性的问题来理解场景,等到能理解到位、能回答了再回答原问题。本文受此启发,提出的动态VQA模型能够提出查询以获取问答任务所需的支撑依据。
本文的动态VQA模型能迭代式地查询新依据并收集外部源中的相关依据。
 An illustration of a standard VQA model. (b) An overview of our iterative model. (c) Detailed flowchart of our model. The model consists of two major components: core network (green) and query generator (blue). The query generator proposes task-driven queries to fetch evidence from external sources. Acquired knowledge is encoded and stored as memories in the core network for answering a question.")
具体而言,本文的模型通过对知识源(knowledge sources)的一系列查询(queries)获取支撑依据。获取到的依据被编码存储进记忆银行(memory bank)。随后,模型使用刚更新的记忆来提出下一轮的查询,或给出目标问题的答案。
2017 Learning to Disambiguate by Asking Discriminative Questions
Li Y, Huang C, Tang X, et al. Learning to disambiguate by asking discriminative questions[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 3419-3428.
人类能够通过问问题来了解信息,认知世界并消解歧义。本文受此启发,提出一种新研究问题——“如何生成有判别力的问题(discriminative questions)来帮助消解视觉实例的歧义?”。

给定一对歧义图片: 1. 分别提取视觉语义属性; 2. 属性及其分值通过选择模块选择出最有区别性的属性对,能够反映两张图之间最明显的区别; 3. 把视觉特征和选出的属性对输入属性条件LSTM生成问题。
2017 Learning to Reason End-to-End Module Networks for Visual Question Answering
Hu R, Andreas J, Rohrbach M, et al. Learning to reason: End-to-end module networks for visual question answering[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 804-813.
基于近期提出的神经模块网络架构(Neural Module Network architecture, NMN),本文提出端到端模块网络(End-to-End Module Networks, N2NMNs),在不使用NMN中的解析器的情况下,通过预测特定实例网络布局。
本文的模型能够模仿专家示范,学习生成网络结构,同时根据下游任务损失来学习网络参数。

根据问题构建网络——根据问题语句预测出需要做哪些操作,每一个操作都通过一个子网络实现,一串子网络形成模块神经网络,用于解决当前问题所需的任务。具体地: 1. 首先计算问题的深度表示; 2. 基于RNN实现的布局预测策略根据问题的深度表示,输出一个确定模块神经网络的模板的结构化动作序列,以及一个从输入语句中提取神经网络参数的注意力动作序列; 3. 网络构建器根据结构化动作序列和注意力动作序列,动态实例化出一个恰当的神经网络,由此根据图像取得答案。
2017 Making the V in VQA Matter Elevating the Role of Image Understanding in Visual Question Answering
Goyal Y, Khot T, Summers-Stay D, et al. Making the V in VQA matter: Elevating the role of image understanding in Visual Question Answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 6904-6913.
VQA被数据中的天然规律和语言因素带偏了,训练出的VQA模型在根据数据中的统计规律(自然规律、语言规律)作答,而忽视了视觉因素。
本文强调视觉问答VQA中视觉的重要性。

具体地,本文为每一个问题找一对语义互补的图像,实现正负例平衡(例如:man/woman, yes/no),避免VQA模型受到视觉无关的统计规律影响。本文的全平衡数据集为VisualQA数据集。
2017 MarioQA Answering Questions by Watching Gameplay Videos
Mun J, Hongsuck Seo P, Jung I, et al. Marioqa: Answering questions by watching gameplay videos[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 2867-2875.
本文研究视频问答VideoQA问题。本文提出一个视频问答模型的分析框架,该框架通过自动生成的游戏视频构建出合成数据集,用该数据集分析模型不同层面的表现。
 target event is selected (marked as a green box), (b) question semantic chunk is generated from the target event, (c) question template is sampled from template pool, and (d) QA pairs are generated by filling the template and the linguistically realizing answer.")
本文根据超级马里奥兄弟游戏生成了一个合成视频问答数据集。
2017 Multi-level Attention Networks for Visual Question Answering
Yu D, Fu J, Mei T, et al. Multi-level attention networks for visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 4709-4717.
本文认为现有方法主要从抽象的低层视觉特征推测答案,而忽视了建模高层图像语义及图中区域的丰富空间上下文语义。
本文提出一个多层注意力网络,通过语义注意力以及基于视觉注意力的细粒度空间推理来缩小语义鸿沟,解决VQA问题。具体地, 1. 从CNN的高层语义生成语义概念(semantic concepts),并选出与问题相关地概念作为语义注意力(semantic attention)。 2. 通过双向RNN把基于区域的CNN中层输出编码为空间嵌入表示,并用MLP进一步定位与回答相关的区域作为视觉注意力(visual attention)。 3. 联合优化语义注意力、视觉注意力和问题嵌入,通过softmax分类器取得答案。
 semantic attention, (B) context-aware visual attention and (C) joint attention learning. Here, we denote by vq the representation of the question Q, by vimg, vc the representation of image content on the visual and semantic level queried by the question, respectively. vr and pimg c is the activation of the last convolutional layer and the probability layer from the CNN.")
其中\(v_{img}\)和\(v_{c}\)都是图像表示,但分别由各区域嵌入和各语义概念而来:
- \(v_{img}\):从CNN中层输出编码为空间嵌入表示(各区域的图像表示),并通过视觉注意力取得的图像表示;
- \(v_{c}\):从CNN的高层语义生成语义概念(semantic concepts),并通过语义注意力选择后的图像表示。
2017 Multi-modal Factorized Bilinear Pooling with Co-attention Learning for Visual Question Answering
Yu Z, Yu J, Fan J, et al. Multi-modal factorized bilinear pooling with co-attention learning for visual question answering[C]//Proceedings of the IEEE international conference on computer vision. 2017: 1821-1830.
本文提出多模态因子分解双线性池化方法(Multi-modal Factorized Bilinear (MFB) pooling approach),提高多模态特征融合能力,以改进VQA。
图像中的视觉特征和问题中的文本特征尽管都可用特征向量表示,但两者概率分布差异很大,简单的拼接和主元素相加可能不足以融合两种模态的特征。因此,双线性模型被提出以解决该问题。

Multi-modal Compact Bilinear pooling (MCB)对两个特征向量做外积,因二次方膨胀产生了非常高维的特征向量。MLB通过低阶映射矩阵改进了高维问题。
Multi-modal Low-rank Bilinear Pooling (MLB): \[ z = MLB(x,y)=(U^Tx)\circ(V^Ty) \]
- x通过矩阵U变换为o维向量;
- y通过矩阵V变换为o维向量;
- 随后两个o维向量做逐元素相乘,取得o维向量z。
本文认为MLB又存在收敛缓慢问题,因此提出MFB。
最简多模态双线性模型: \[ z_i = x^T W_i y \]
- \(x \in \mathbb{R}^m\),\(y \in \mathbb{R}^n\),\(W_i \in \mathbb{R}^{m \times n}\)
Multi-modal Factorized Bilinear pooling (MFB): \[ z_i = x^TU_iV_i^Ty = \sum^k_{d=1}x^Tu_dv_d^Ty = \mathbb{1}^T(U_i^Tx \circ V_i^Ty) \] 或写作: \[ z = \mathrm{SumPooling}(\tilde{U}^Tx \circ \tilde{V}^Ty, k) \]
2017 Multimodal Learning and Reasoning for Visual Question Answering
Ilievski I, Feng J. Multimodal learning and reasoning for visual question answering[C]//Advances in Neural Information Processing Systems. 2017: 551-562.
本文认为VQA研究现状大多是用LSTM理解问题、用CNN表示图像。这种单个视觉表示能包含的信息有限,且只能表示图像的笼统内容,会制约模型的推理能力。
本文提出一个模块化神经网络模型ReasonNet,能够学习多模态、多方面(multifaceted)的图像和问题表示。
本文对VQA问题的形式化定义:
Namely, the VQA problem can be solved by modeling the likelihood probability distribution \(p_{vqa}\) which for each answer \(a\) in the answer set \(\Omega\) outputs the probability of being the correct answer, given a question \(Q\) about an image \(I\):
\[ \hat{a} = \mathop{\arg\max}_{a\in\Omega} p_{vqa}(a|Q,I;\theta) \]
使以\(\theta\)为参数的模型的似然概率分布 \(p_{vqa}\) 在输入问题\(Q\)、图像\(I\)的条件下,输出正确答案\(a\)的概率最大。
), thin rectangles represent the learned multimodal representation vectors, x represents the bilinear interaction model (Eq. (4)), and the big trapezoid is a multi-layer perceptron network that classifies the reasoning vector g to an answer a (Eq. (7))")
- 圆角矩形表示注意力模块;
- 方角矩形表示分类模块;
- 斜方形(trapezoid)表示编码器单元;
- 符号\(\otimes\)表示双线性交互模型(bilinear interaction model);
- 大斜方形表示多层感知机网络,即最终的答案分类网络。
ReasonNet通过多个模块(注意力模块、分类模块)对图像和问题做处理,处理结果在编码后做双线性交互(bilinear interaction),最终取得的各个向量连接为长向量,用于最后的回答分类器做分类。
2017 MUTAN Multimodal Tucker Fusion for Visual Question Answering
Ben-Younes H, Cadene R, Cord M, et al. Mutan: Multimodal tucker fusion for visual question answering[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2612-2620.
本文提出MUTAN,多模态的基于张量的Tucker分解,能够有效参数表示视觉与文本表示之间的双线性交互。
本文MUTAN的目的在于控制合并模式的复杂度,同时保持对融合关系的优良可解释性。

Tucker分解:本文的方法基于对协相关张量的Tucker分解,能够表示全双线性互动,同时维持易处理模型的尺寸。
2017 Structured Attentions for Visual Question Answering
Zhu C, Zhao Y, Huang S, et al. Structured attentions for visual question answering[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1291-1300.
本文认为VQA的问题很可能牵涉到多个图像区域之间的复杂关系,而现在很少有注意力模型能够有效编码跨区域关系(cross-region relations)。
本文通过展示ResNet作用有限的感受野,说明编码区域间关系的重要性。因此,本文提出把图像区域上的视觉注意力建模为网格结构条件随机场(CRF)上的多变量分布。本文解释了如何把迭代推理算法(Mean Field和Loopy Belief Propagation)转换为端到端神经网络的循环层。
 and pairwise potential ψij(zi, zj), computed with Eq. 8. ψi(zi) can also be used as an additional glimpse, which usually detects the key nouns. In the inference layers, xi represents b(i) for MF and m(i) for LBP. The recurrent inference layers generates a structured glimpse with MF or LBP. The 2 glimpses are used to weight-sum the visual feature vectors. The classifier use both of the attended visual features and the question feature to predict the answer. The demonstration is a real case.")
2017 TGIF-QA Toward Spatio-Temporal Reasoning in Visual Question Answering
Jang Y, Song Y, Yu Y, et al. Tgif-qa: Toward spatio-temporal reasoning in visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2758-2766.
本文研究如何把当前主要面向图像的VQA拓展到面向视频。本文认为现有的视频VQA研究仅仅是在图像VQA的基础上对现有内容增加了一些描述动作的动词,或者提高了对理解长文本的要求,没有真正地深入研究推理能力。
本文主要工作:
- 为视频VQA提出三种新的研究方向,需要从视频到答案的时空推理能力。
- 重复计数(Repetition count):回答一个动作发生了多少次;
- 重复动作(Repeating action):回答视频中重复的动作是什么;
- 状态转换(State transition):回答例如:表情、动作、地点、目标属性的状态转换情况。
- 本文给出了一个视频VQA的大型数据集——TGIF-QA。
- 本文提出了一个基于双LSTM的方法,包含空间和时间注意力。

2017 The VQA-Machine Learning How to Use Existing Vision Algorithms to Answer New Questions
Wang P, Wu Q, Shen C, et al. The vqa-machine: Learning how to use existing vision algorithms to answer new questions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1173-1182.
实现VQA实际上需要对图像做大量操作,例如:目标检测、计数、分割和重构。本文认为依靠现有的VQA数据量就想要训练一个集各种能力于一身的模型过于贪心,不如把现有的各个方向的已经训练好的模型拿来组合。
本文提出的模型是一种新的协同注意力(co-attention)模型。本文提出的方法还能够为决策结果生成人类可读的理由,且无需理由的真值也能端到端训练。
 classifier is used to predict answers. Then the ranked facts are used to generate reasons.")
模型输入:问题、视觉事实(visual facts)、图像;
- 问题经过层次问题编码(Hierarchical Question Encoding)表示,包含三层:单词、短语、句子;
- 视觉事实通过三元组(subject, relation, object)表示;
- 图像划分区域,计算区域注意力。
三个输入在问题编码的三个级别(\(Q^w\)、\(Q^P\)、\(Q^q\))做协同注意力加权。
MLP分类器根据协同注意力加权后的特征进行分类,预测答案。
模型对输入的视觉事实进行排序,用于生成理由。
, facts (F) and image (V), this module sequentially generates weighted features (˜v, ˜q,˜f ).")
本文的顺序协同注意力(Sequential Co-attention)机制指的是每次用其余特征作为导向,生成某个特征的注意力权重。可形式化为: \[ \hat{x} = \mathrm{Atten(X, g_1, g_2)} \] 计算原理为: \[ \mathrm{H}_i = \tanh(\mathrm{W}_x\mathrm{x}_i+\mathrm{W}_{g_1}\mathrm{g}_1+\mathrm{W}_{g_2}\mathrm{g}_2), \\ \mathrm{\alpha}_i = \mathrm{softmax}(\mathrm{w^\top}\mathrm{H}_i), i=1,...,N, \\ \mathrm{\hat{x}} = \sum^N_{i=1}\alpha_i\mathrm{x}_i, \] 其中,\(\mathrm{X}\)是输入序列,比如:问题\(\mathrm{Q}\)、事实\(\mathrm{F}\)或图像\(\mathrm{V}\),而\(\mathrm{g_1}, \mathrm{g_2} \in \mathbb{R}^d\)表示先前注意力模块的输出,此处作为注意力导向(guidance)。
2017 Video Question Answering via Hierarchical Spatio-Temporal Attention Networks
Zhao Z, Yang Q, Cai D, et al. Video question answering via hierarchical spatio-temporal attention networks[C]//Proceedings of the 26th International Joint Conference on Artificial Intelligence. AAAI Press, 2017: 3518-3524.
本文认为当前VQA研究着眼于静态图像,现有方法无法有效应对视频问答,因为没有对视频内容中的时间动力学(temporal dynamics)进行建模。
本文从时空注意力编解码器学习框架(spatio-temporal attentional encoder decoder learning framework)着手,提出层次时空注意力网络(hierarchical spatio-temporal attention network),根据给定问题,学习动态视频内容的联合表示。本文开发了包含多步推理流程的时空注意力网络用于视频问答。
. The hierarchical spatio-temporal attentional encoder networks learn the joint representation of multimodal spatio-temporal attentional video and textual question with multiple reasoning steps, and the recurrent decoder network generates the natural language answer for open-ended video question answering.")
2017 VQS Linking Segmentations to Questions and Answers for Supervised Attention in VQA and Question-Focused Semantic Segmentation
Gan C, Li Y, Li H, et al. Vqs: Linking segmentations to questions and answers for supervised attention in vqa and question-focused semantic segmentation[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1811-1820.
本文把COCO数据集中的实例分割标注和VQA数据集中的问题和答案标注联系起来,命名为VQS(Visual Questions and Segmentation answers)数据集。新的实例分割标注可能有助于开辟新的研究问题和模型。

2017 What's in a Question Using Visual Questions as a Form of Supervision
Ganju S, Russakovsky O, Gupta A. What's in a question: Using visual questions as a form of supervision[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 241-250.
本文研究弱监督学习。
本文认为已有研究已经挖掘了很多弱监督学习标注信息,如:弱手工标注、网络搜索结果、时间连续性、显著声音等。本文关注于一项尚未发掘出的若监督学习模式:图像被问到的问题。
本文认为即使没有答案,图像对应的问题本身其实就已经提供了有关图像的信息。
 visual image features, (2) text embedding of the target question, and (3) text embedding of the other questions concatenated together. This representation is passed through a learned fully connected layer to predict the answer to the target question.")
iBOWING-2x模型。输入包含三部分: 1. 视觉图像特征; 2. 目标问题的文本嵌入; 3. 其它问题连接起来后的文本嵌入。 // 增加了图像的其它问题作为弱监督学习信息
2018 Chain of Reasoning for Visual Question Answering
Wu C, Liu J, Wang X, et al. Chain of reasoning for visual question answering[C]//Advances in Neural Information Processing Systems. 2018: 275-285.
本文研究VQA中的推理(reasoning)。
本文认为回答复杂的VQA问题需要多步且动态的推理,而已有研究只支持单步或静态推理,无法更新关系或生成复合目标。
本文构造了一个推理链(chain of reasoning, CoR)模型,支持对变化的关系和目标实现多步、动态推理。具体地,关系推理操作形成目标间新的关系,而目标修正操作从关系中生成新的复合目标。
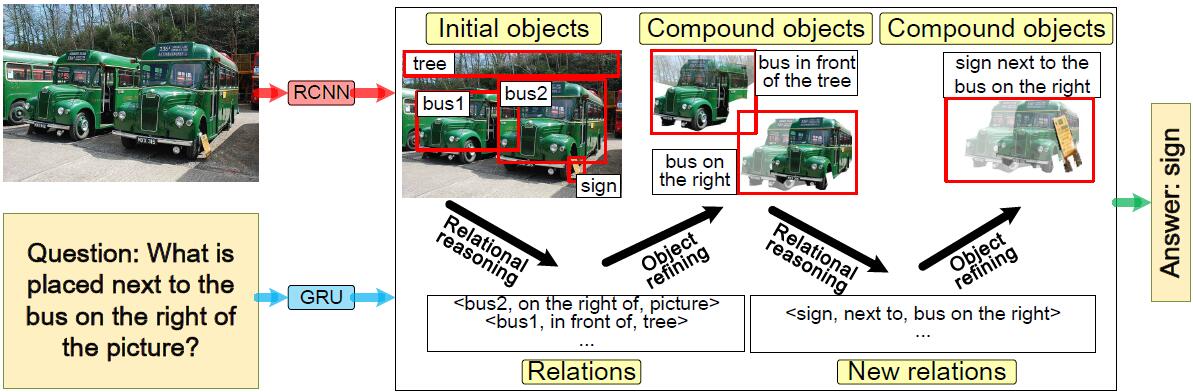
本文构造的推理链模型中,关系(relation)和复合目标(compound objects)都是推理链中的节点。 关系的更新使得推理面向更多复合目标,而复合目标又是推理链的阶段性结论,可以有效降低下一步的关系推理的计算复杂度。(关系推理->复合目标推理->关系推理->……)
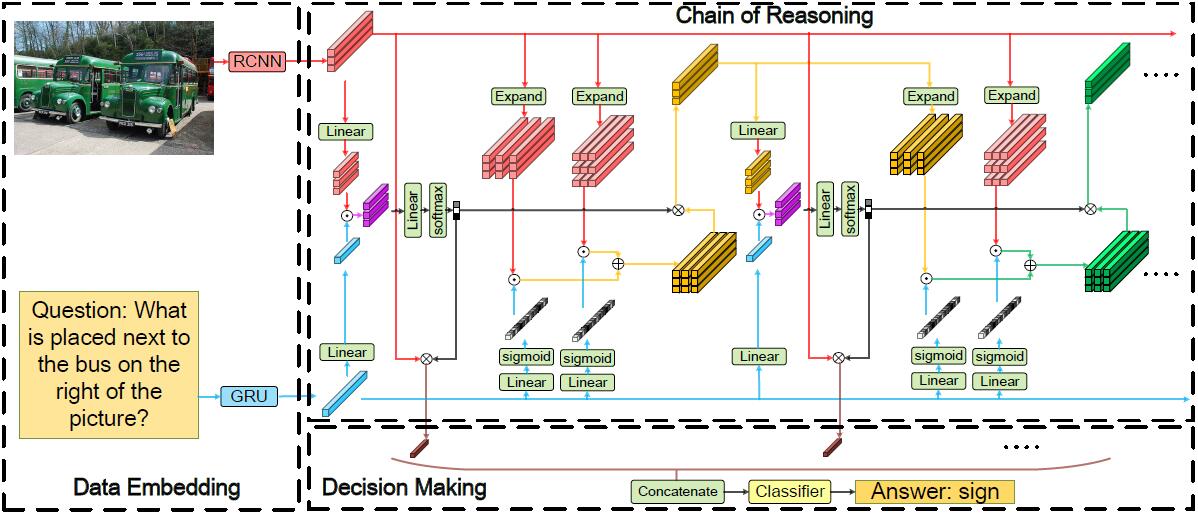
整体模型包含数据嵌入、推理链、决策生成三部分。
形式化表述上,推理链是由若干条子链(sub-chain)构成的,从\(t\)时刻的复合目标集合\(O^{(t)}\),到推理出\(t\)时刻的关系集合\(R^{(t)}\),再基于关系进一步推理\(t+1\)时刻的复合目标集合\(R^{(t+1)}\)。其中,\(O^{(t)} \in \mathbb{R}^{m \times d_v}\),\(R^{(t)} \in \mathbb{R}^{m \times m \times d_v}\),\(O^{(t+1)} \in \mathbb{R}^{m \times d_v}\)。
从\(O^{(t)}\)到\(R^{(t)}\)的关系推理(relational reasoning)可表述为: \[ G_l = \sigma(relu(QW_{l_1})W_{l_2}), \\ G_r = \sigma(relu(QW_{r_1})W_{r_2}), \\ R_{ij} = (O_i^{(t)} \odot G_l) \oplus (O_j^{(1)} \odot G_r), \]
- \(O^{(t)}\)中的\(m\)的目标在问题\(Q\)的指导下与初始目标集\(O^{(1)}\)中的\(m\)个目标交互。
从\(R^{(t)}\)到\(O^{t+1}\)的目标修正可表述为: \[ O_j^{t+1} = \sum^m_{i=1}\alpha_i^{(t)}R_{ij}^{(t)} \]
2018 Cross-Dataset Adaptation for Visual Question Answering
Chao W L, Hu H, Sha F. Cross-dataset adaptation for visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 5716-5725.
本文研究VQA的跨数据集适配问题。本文希望能够在一个源数据集上训练VQA模型,然后再应用到另一个目标数据集上。//因为目标领域的数据集往往数据量有限。
本文提出了一款领域适配算法(domain adaptation algorithm)。该算法通过变换目标数据集中数据的特征表示,来缩小源数据集与目标数据集之间的统计分布差异。另外,该算法还能够使在源数据集上训练的VQA模型在目标数据集上回答正确时似然概率最大。
 and Visual7W [50] (left) provide different styles of questions, correct answers (red), and candidate answer sets, each can contributes to the bias to prevent cross-dataset generalization.")
2018 Customized Image Narrative Generation via Interactive Visual Question Generation and Answering
Shin A, Ushiku Y, Harada T. Customized Image Narrative Generation via Interactive Visual Question Generation and Answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8925-8933.
本文认为人在描述图像时,关注的方面时不一样的,因此会给出不同的描述。
本文提出一个自定义图像叙述生成任务(customized image narrative generation task),用户通过回答给出的问题来叙述图像。

2018 Differential Attention for Visual Question Answering
Patro B, Namboodiri V P. Differential attention for visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 7680-7688.
已有的注意力研究都是通过关注某一个图像区域来回答问题,而本文认为已有研究的注意力机制关注的区域与人类会关注的图像区域并不相关。
因此,本文提出通过一或多个支持和反对范例来取得一个微分注意力区域(differential attention region)。 与基于图像的注意力方法比起来,本文计算出的微分注意力更接近人类注意力,因此可以提高回答问题的准确率。
在认知研究中的范例理论(exexplar theory)里,个体会拿新刺激和记忆中已知的实例作比较,并基于这些范例找到回答。本文的目的就是通过范例模型来取得注意力。本文的前提是,语义最近的范例和远语义范例之间存在差异,这样的差异能够引导注意力关注于一个特定的图像区域。

原理流程:
- 根据输入图像和问题取得引用注意力嵌入(reference attention embedding);
- 根据该引用注意力嵌入,在数据库中找出样本,取近样本作为支持范例、远样本作为反对范例;
- 支持范例和反对范例用于计算微分注意力向量;
- 通过微分注意力网络(differential attention network, DAN)或微分上下文网络(differential context network)分别可以改进注意力或取得微分上下文特征,这两种方法可以提升注意力与人工注意力的相关性;
2018 Don't Just Assume; Look and Answer Overcoming Priors for Visual Question Answering
Agrawal A, Batra D, Parikh D, et al. Don't just assume; look and answer: Overcoming priors for visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4971-4980.
本文认为现有的VQA模型在回答问题时缺乏充足的图像依据。(倾向于依赖语言层面的条件,而非以图像为根据回答问题)
本文提出通过把训练集和测试集的“回答”的概率分布差异化开来,可以验证VQA模型是否收到了语料数据(问题、回答)概率分布的偏差影响,变得倾向于根据预料中的概率分布来回答问题,而非以图像为依据。
本文提出视觉根据问答模型(Grounded Visual Question Answering model, GVQA)
 model.")
本文的GVQA会对问题语句做出分类,判断其是否是一个“回答yes/no”的问题。 视觉概念分类器(Visual Concept Classifier, VCC)在任何情况下都工作,但回答聚类预测器(Answer Cluster Predictor, ACP)和概念抽取器(Concept Extractor, CE)是二选一的。回答预测器(Answer Predictor, AP)和视觉验证器(Visual Verifier, VV)也是二选一的。
当给定图像和问题作为输入时:
- 如果不是“yes/no”型问题,那么ACP工作,而CE不工作。ACP从问题语句中预测出的概念据类输入到AP中,给出998预定义回答词的分类结果。
- 如果是“yes/no”型问题,那么CE工作,ACP不工作,VCC和CE输入到VV中,给出Yes/No的分类结果。
2018 DVQA Understanding Data Visualizations via Question Answering
Kafle K, Price B, Cohen S, et al. DVQA: Understanding data visualizations via question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 5648-5656.
本文提出数据可视化问答(Data Visualizations Question Answering, DVQA),并给出DVQA数据集,包含基于问答框架的对条形图(bar charts)的各种层面的理解。
 for DVQA. MOM uses two sub-networks: 1) classification sub-network that is responsible for generic answers, and 2) OCR sub-network that is responsible for chart-specific answers.")
本文的DVQA多输出模型(Multi-Output Model, MOM)包含两个子网络:
- 分类子网络:生成一般回答;
- OCR子网络:生成针对图表的回答。
2018 Embodied Question Answering
Das A, Datta S, Gkioxari G, et al. Embodied question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2018: 2054-2063.
本文提出一个新任务——EmbodiedQA,其中的智能体被放置在三维环境中的一个任意地点并且被问一个问题。智能体需要智能导航探索所处环境,通过第一视角找出必要的视觉信息,随后才能找出问题的答案。

The embodiment hypothesis is the idea that intelligence emerges in the interaction of an agent with an environment and as a result of sensorimotor activity.
-Smith and Gasser, “The development of embodied cognition: six lessons from babies.,” Artificial life, vol. 11, no. 1-2, 2005.
2018 Focal Visual-Text Attention for Visual Question Answering
Liang J, Jiang L, Cao L, et al. Focal visual-text attention for visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6135-6143.
本文研究真实生活中的VQA问题,研究一组图片序列或视频(算是Video VQA),来回答问题,而不是传统的一张静态图片。
本文提出焦点视觉文本注意力网络(Focal Visual-Text Attention network, FVTA)。本文的FVTA模型解决的是如何关注序列数据中与问题相关部分的问题。FVTA模型不仅能回答问题,还能给出回答的理由。
 model. For visual-text embedding, we use a pre-trained convolutional neural network to embed the photos and pre-trained word vectors to embed the words. We use a bi directional LSTM as the sequence encoder. All hidden states from the question and the context are used to calculate the FVTA tensor. Based on the FVTA attention, both question and the context are summarized into single vectors for the output layer to produce final answer. The output layer is used for multiple choice question classification. The text embedding of the answer choice is also used as the input. This input is not shown in the figure.")
2018 FVQA Fact-Based Visual Question Answering
Wang P, Wu Q, Shen C, et al. Fvqa: Fact-based visual question answering[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 40(10): 2413-2427.
本文认为已有的VQA研究大多直接分析问题和图像,无需外部信息,这使其无法应对需要例如:常识、基本事实知识等信息的问题。
本文提出基于事实的视觉问答FVQA(Fact-based VQA)数据集,该数据集包含了需要外部信息才能回答的问题,能够支撑更深层的推理研究。
每一个支持事实都通过结构化三元组表示,如:<Cat, CapbleOf, ClimbingTrees>。
 of the input image are extracted using trained models, which are further linked to the corresponding semantic entities in the knowledge base. The input question is first mapped to one of the query types using the LSTM model shown in Section 4.2. The types of key relationships, key visual concept and answer source can be determined accordingly. A specific query (see Section 4.3) is then performed to find all facts meeting the search conditions in KB. These facts are further matched to the keywords extracted from the question sentence. The fact with the highest matching score is selected and the answer is also obtained accordingly.")
首先,图像和视觉概念的收集方面,本文从微软COCO数据集的验证集和ImageNet的测试集中采样了2190张图像。微软COCO数据集中的图像提供更多的上下文信息,而ImageNet中的图像内容更简单,但包含更多的目标类型。(200 in ImageNet versus 80 in Microsoft COCO)。本文在2190个图像上,通过人工标注建立了5826个问题,含32个问题类型。

本文使用的外部结构化知识库来源于:DBpedia、ConceptNet和WebChild。
- DBpedia,通过众包从维基百科中抽取的结构化知识。本文使用其中的视觉概念的类属关系(concepts are linked to their categories and super-categories based on the SKOS Vocabulary)。
- ConceptNet,从Open Mind Common Sense (OMCS) 项目中的句子中自动生成。由几种常识关系(commonsense relations)组成,如:UsedFor, CreatedBy, IsA。本文使用其中的11种常见关系。
- WebChild,从Web中自动抽取生成,一个被忽视(overlooked)的常识事实库,涉及比较关系(comparative relations),如:Faster, Bigger, Heavier。
本文提出的FVQA数据集中,“问题”是通过一个标注系统来人工输入的,标注过程分三步: 1. 选择概念(Selecting Concept):给定图像及其中的一些视觉概念(目标、场景和行为),标注者需要从中选出一项视觉概念; 2. 选择事实(Selecting Fact):特定视觉概念被选定后,系统给出与该视觉概念相关的一些事实。标注人员需要选出一项正确的且与图像相关的事实。 3. 问问题并给答案(Asking Question and Giving Answer):根据选出的视觉概念和事实,标注者需要提出一个问题,并给出答案。提出的问题必须是要同时依靠图像信息和事实信息才能回答的问题,而该问题的答案则必须是选定事实中的两个概念的其中之一,即,答案要么是第一步选出的视觉概念,要么是第二步选出的事实中的相关概念。
2018 Improved Fusion of Visual and Language Representations by Dense Symmetric Co-attention for Visual Question Answering
Nguyen D K, Okatani T. Improved fusion of visual and language representations by dense symmetric co-attention for visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6087-6096.
已有研究存在注意力机制和特征融合两条路线分别研究的问题,本文认为更好的注意力机制能够带来更好的融合表示。
本文发现两种模态之间密集、双向互动的注意力机制能够提高VQA准确率。
本文提出了一个简单的架构,在该架构中,视觉表示和语言表示完全对称,问题中的每一个单词关注到图像中的区域,图像中的每一个区域关注到问题中的单词。该架构还可以堆成层次结构,用于建模图像-问题对之间的多步互动。

本文设计的注意力层称为密集协同注意力层(dense co-attention layer)。 给定一个图像和对应的一个问题,本文的密集协同注意力层为问题中的每个单词生成各图像区域的注意力图,同样地,反过来也为图像中的每一个区域生成问题中各单词的注意力图。随后,计算注意力加权的特征,连接多模态表示,以及做后续变换。 本文的密集协同注意力层考虑了任意图像区域与任意问题单词之间的每一个交互关系。事实上,形成了两种模态之间的全对称架构,并且还可以堆成层次结构以建模图像与问题之间的多部互动关系。
另外,本文还提到了对注意力机制的特殊情况:“没什么好注意的”的处理方法,即,为N个问题单词和T个图像区域都增加K个元素。
2018 IQA Visual Question Answering in Interactive Environments
Gordon D, Kembhavi A, Rastegari M, et al. Iqa: Visual question answering in interactive environments[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4089-4098.
本文提出交互问答(Interactive Question Answering, IQA)任务,在该任务中,智能体需要与一个动态的视觉环境交互来回答问题。
")
2018 iVQA Inverse Visual Question Answering
Liu F, Xiang T, Hospedales T M, et al. iVQA: Inverse visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8611-8619.
本文首次提出逆视觉问答任务iVQA,作为“视觉-语言”理解的一项指标。
逆视觉问答iVQA任务是指根据给定的图像和答案,生成对应的问题。

2018 Learning Answer Embeddings for Visual Question Answering
Hu H, Chao W L, Sha F. Learning answer embeddings for visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 5428-5436.
本文为VQA提出一款新的概率模型。 核心思想是推测两组嵌入:
图像和问题的嵌入;
回答的嵌入。
学习目标是习得最佳参数,能够使得正确答案在所有可能答案中由最高的似然概率。
 and (possible) answer a into a joint embedding space. The distance (by inner products) between the embedded (i, q) and a is then measured and the closest a (in red) would be selected as the output answer.")
把“图像+问题”和“回答”映射到联合嵌入空间中,对应的图像问题对(i,q)和对应的正确答案a的距离应最短。
2018 Learning by Asking Questions
Misra I, Girshick R, Fergus R, et al. Learning by asking questions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 11-20.
本文为智能视觉系统提出交互式学习框架,命名为learning-by-asking(LBA)。
本文在VQA的问题场景下研究LBA。相较于标准VQA在训练过程中学习大量问答,LBA中的学习者(智能体)则需要在/自主问问题来获取它想知道的知识。

给定一个图像\(I\),智能体: 1. 问题生成器(Question Generator)\(g\)根据图像\(I\)一个问题集合; 2. 问题相关性(Question Relevance)\(r\)则作为筛选依据选出一列问题提议\(Q_p\); 3. 问题回答模块(Question Answering Module)中,智能体自己的VQA模型\(v\)负责回答问题提议\(Q_p\); 4. 根据预测出的答案以及智能体已经取得的自我知识,问题选择模块(Question Selection Module)从问题提议\(Q_p\)中选出一个问题来问先知(Oracle); 5. 先知回答该选出的问题,答案作为监督标记帮助智能体在下一轮提出有意义的问题。
2018 Learning Conditioned Graph Structures for Interpretable Visual Question Answering
Norcliffe-Brown W, Vafeias S, Parisot S. Learning conditioned graph structures for interpretable visual question answering[C]//Advances in Neural Information Processing Systems. 2018: 8334-8343.
现有的研究很少有基于高层图像表示的,很少去捕捉语义和空间关系。现有的VQA研究大多扑在创造新的注意力架构上,而没有去建模场景中的目标之间语义关系。对于现有的典型的场景图生成研究【2017 Scene Graph Generation by Iterative Message Passing】(研究场景图自动生成方法的论文),本文认为场景图通过图结构表示图像,能够显式建模互动关系,例如图像中的目标及其互动关系,由此在近期的VQA研究中很受关注。但另一方面,本文认为现有的场景图研究需要大量工程量,而且是针对特定图像的而不是针对问题,还存在难以从虚拟场景迁移到真实图像、可解释性差的问题。
本文提出一种基于图的VQA方法,本文的方法加入了一个图学习模块(graph learner module),能够学习输入图片对特定问题的图表示(question specific graph representation)。具体地,本文的方法通过图卷积,学习能够捕捉与问题相关的互动信息的图像表示。
对同一个图像,不同的问题产生了不同的图结构。图结构针对不同问题指向相应的答案。

本文方法的核心在于图学习器(graph learner)。 输入:
问题编码;
一组目标的边界框及其目标图像特征向量;
输出:以问题为条件的图像的图表示,并建模目标之间的相互关系。
图学习器的具体原理为:
本文提出了一种根据问题上下文学习取得的图结构。具体地,该图结构表示中,把目标检测地边界框定义为图节点,而以问题为条件地图边则通过基于注意力机制地模块学习取得。就定义而言,本文的图结构是一种无向图,定义为\(G = \{ V, ε, A \}\),包含节点集\(V\),待学习的边集\(\epsilon\),以及节点之间的邻接矩阵\(A \in \mathbb{R}^{N×N}\)。邻接矩阵\(A\)用于表示边\((i, j, A_{i,j}) \in \epsilon\),该矩阵\(A\)的值以问题编码\(q\)为条件。
具体地,本文通过把节点的视觉特征\(v_n\)和问题编码\(q\)连接起来,记为\([v_n || q]\),并通过非线性函数\(F:\mathbb{R}^{d_v+d_q} \to \mathbb{R}^{d_e}\)映射为联合嵌入\(e_n\),形式化为:
\[ e_n = F([v_n||q]), n = 1,2,...,N \]
接下来,节点\(i\),\(j\)之间的邻接矩阵值通过\(A_{i,j}=e_i^Te_j\),即向量内积求取相似度计算取得,可以通过矩阵运算\(A=EE^T\)实现。
邻接矩阵\(A\)是一个全连接的邻接矩阵,这样的邻接矩阵\(A\)及由此计算边集$ \(的定义没有对图的稀疏性(sparsity)做任何约束。这种全连接的密集边集不仅计算量大,而且对VQA没有帮助,因为VQA需要的是关注与问题有关的节点。把邻接矩阵\)A\(学习到的图结构作为图卷积层(graph convolution layers)的backbone,在做图卷积计算之前应该先筛选,关注与VQA任务相关的一部分节点和边,而不需要所有节点之间的关系。因此本文通过\)topm\(排序\)m\(个最大\)a\(值,对邻接矩阵\)A$进行筛选,取得一个稀疏的、保留强关联的边的边集合。此处的形式化表述为:
\[ N(i) = topm(a_i) \]
2018 Learning to Specialize with Knowledge Distillation for Visual Question Answering
Mun J, Lee K, Shin J, et al. Learning to specialize with knowledge distillation for visual question answering[C]//Advances in Neural Information Processing Systems. 2018: 8081-8091.
本文研究VQA中的知识蒸馏(Knowledge Distillation)。
Visual Question Answering (VQA) is a notoriously challenging problem because it involves various heterogeneous tasks defined by questions within a unified framework. Learning specialized models for individual types of tasks is intuitively attracting but surprisingly difficult; it is not straightforward to outperform naïve independent ensemble approach. We present a principled algorithm to learn specialized models with knowledge distillation under a multiple choice learning (MCL) framework, where training examples are assigned dynamically to a subset of models for updating network parameters. The assigned and non-assigned models are learned to predict ground-truth answers and imitate their own base models before specialization, respectively. Our approach alleviates the limitation of data deficiency in existing MCL frameworks, and allows each model to learn its own specialized expertise without forgetting general knowledge. The proposed framework is model-agnostic and applicable to any tasks other than VQA, e.g., image classification with a large number of labels but few per-class examples, which is known to be difficult under existing MCL schemes. Our experimental results indeed demonstrate that our method outperforms other baselines for VQA and image classification.

2018 Learning Visual Knowledge Memory Networks for Visual Question Answering
Su Z, Zhu C, Dong Y, et al. Learning visual knowledge memory networks for visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 7736-7745.
本文把VQA数据样本中的目标分为三类:
- 明显目标(apparent objective):从图像中可以直接回答出来;
- 隐约目标(indiscernible objective):视觉识别不清,需要借助常识作为约束;
- 不可见目标(invisible objective):无法借助视觉内容回答,需要对外部知识做归纳/推理才行。
对于隐约目标、不可见目标,VQA需要从结构化的人类知识中进行推理,并根据视觉内容进行确认。
本文提出视觉知识记忆网络(visual knowledge memory network, VKMN),VKMN能够在端到端学习框架下,把结构化的人类知识和深度视觉特征无缝整合进记忆网络中。
本文关注点:
把视觉内容和知识事实做集成的机制。VKMN模型通过把知识三元组(subject, relation, target)和深度视觉特征联合嵌入进视觉知识特征的方式实现该机制。
处理从问题和答案对中扩展出的多项知识事实的机制。VKMN模型通过键值对结构在记忆网络中存储联合嵌入,以便处理多条事实。
 are used to handle the ambiguity on which part of the knowledge triple is missing in the query question.")

2018 Motion-Appearance Co-Memory Networks for Video Question Answering
Gao J, Ge R, Chen K, et al. Motion-appearance co-memory networks for video question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6576-6585.
视频VQA和图像VQA的区别: 1. 视频VQA需要处理较长的图像序列,其中包含了更加丰富的信息,无论是数量,还是种类,都比图像包含的信息多。 2. 运动和出现信息互相关联,能够相互提供有用的注意力线索; 3. 不同的问题需要不同数量的视频帧来推测答案。
基于视频VQA和图像VQA的区别,本文为视频QA提出一个运动-出现协同记忆网络(motion-appearance co-memory network)。该网络基于动态记忆网络(Dynamic Memory Network, DMN)的概念,并建立了新的机制: 1. 协同记忆注意力机制(co-memory attention mechanism):根据运动和出现线索来生成注意力; 2. 时间卷积-反卷积网络(temporal conv-deconv network):生成多层上下文事实; 3. 动态事实集成方法(dynamic fact ensemble method):动态构建对不同问题的时间表示。

2018 Neural-Symbolic VQA Disentangling Reasoning from Vision and Language Understanding
Yi K, Wu J, Gan C, et al. Neural-symbolic vqa: Disentangling reasoning from vision and language understanding[C]//Advances in Neural Information Processing Systems. 2018: 1031-1042.
本文把推理从视觉及语言理解中解脱出来。本文认为不必纠结在构建视觉理解、语言理解的深度表示中做知识推理。本文认为,通过深度表示学习来实现视觉识别和语言理解,通过符号程序的执行来实现推理。本文提出神经-符号视觉问答(neural-symbolic visual question answering, NS-VQA)系统,首先从图像中构建结构化场景表示,从问题中构建程序跟踪(program trace)。随后,NS-VQA在场景表示上执行程序进行推理并取得答案。
结合符号结构先验知识具备三大优势: 1. 在符号空间中执行程序比长程序跟踪更稳定;(本文呢在CLEVR数据集上acc达99.8%) 2. 数据高效和内存高效:只需要少部分训练数据,还能够把图像转换为紧凑表示(如图2中的表格),因此省内存; 3. 符号程序执行的过程本身具备完全的透明度,因此每一个执行步骤都是可解释、可诊断的。
 that segments an input image (a-b) and recovers a structural scene representation (c); second, a question parser (program generator) that converts a question in natural language (d) into a program (e); third, a program executor that runs the program on the structural scene representation to obtain the answer.")
- 图像--神经网络-->场景表示;
- 问题--生成-->程序跟踪;
- 通过符号程序执行器,和神经解析器配合,执行程序进行推理取得答案。
关于推理的实验基本都在CLEVR数据集上做,但CLEVR数据集毕竟是合成的数据集,都是cube, cylinder之类的东西,不同的相对位置、颜色外观等。NS-VQA方法能泛化至real world的图像么?Minecraft world可能能够在一定程度上验证其泛化能力。本文利用Minecraft生成了1万个游戏画面场景,每个场景3~6个物体目标。当Programs数量达到500时,Accuracy能达到87.3%。
2018 Out of the Box Reasoning with Graph Convolution Nets for Factual Visual Question Answering
Narasimhan M, Lazebnik S, Schwing A. Out of the box: Reasoning with graph convolution nets for factual visual question answering[C]//Advances in Neural Information Processing Systems. 2018: 2654-2665.
基于事实(fact-based)的VQA旨在促进VQA模型对知识的运用。已有研究通过深度学习技术连续缩小大规模事实集,直到剩下最后一条事实,取该事实中两个实体的其中一个作为答案预测出来。 本文观察了这个持续过程,认为每次根据一条事实来形成局部决策是次优(sub-optimal)的。因此,本文开发一种实体图(entity graph),并使用图卷积神经网络GCN来联合考虑所有节点以推理出正确答案。
 to obtain relevant facts from the fact space. An LSTM (2) predicts the relation from the question to further reduce the set of relevant facts and its entities. An entity embedding is obtained by concatenating the visual concepts embedding of the image (3), the LSTM embedding of the question (4), and the LSTM embedding of the entity (5). Each entity forms a single node in the graph and the relations constitute the edges (6). A GCN followed by an MLP performs joint assessment (7) to predict the answer. Our approach is trained end-to end.")
本文的方法: 1. 从事实空间(Fact Space)中取得相关事实; 2. 通过LSTM预测问题中的关系,并用其进一步减少相关事实及实体集合; 3. 通过把图像中视觉概念嵌入(visual concepts embedding)连接起来获得一个实体嵌入; 4. 通过LSTM计算问题嵌入; 5. 通过LSTM计算实体嵌入; 6. 每一个实体作为图中的一个节点,关系则作为边; 7. 通过GCN及后接的MLP来做联合评估以预测答案。
2018 Overcoming Language Priors in Visual Question Answering with Adversarial Regularization
Ramakrishnan S, Agrawal A, Lee S. Overcoming language priors in visual question answering with adversarial regularization[C]//Advances in Neural Information Processing Systems. 2018: 1541-1551.
本文认为现有的VQA模型过度依赖训练数据中问题和答案之间的表层关联,没有真正以图像视觉信息为根据,无法真正适应真实世界场景。
本文为VQA提出一种正则化模式(regularization scheme)。该模式引入一个question-only模型,只取VQA的问题作为输入,该模型必须依赖语言来做预测。该question-only模型继而与VQA模型形成对抗博弈,以此达到让VQA模型在问题编码中避免language biases的作用。
, we introduce two regularizers. First, we build a question-only adversary (B) that takes the question embedding qi from the VQA model and is trained to output the correct answer from this information alone. For this network to succeed, qi must capture language biases from the dataset – the same biases that lead the base VQA model to ignore visual content. To reduce these biases, we set the base VQA model and the question-only adversary against each other, with the base VQA network modifying its question embedding to reduce question-only performance (shown here as gradient negation of the question-only model loss) Further, the question-only model allows estimation of the change in answer confidence given image (C), which we maximize explicitly.")
2018 Textbook Question Answering Under Instructor Guidance With Memory Networks
Li J, Su H, Zhu J, et al. Textbook question answering under instructor guidance with memory networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 3655-3663.
本文研究教科书问答TQA。
本文认为现有的方法难以对长上下文和图像进行有效推理。
本文提出使用记忆网络的导师指导(Instructor Guidance with Memory Networks, IGMN)方法。IGMN方法通过查找候选答案与对应上下文之间的矛盾来实现TQA任务。
本文构造矛盾实体关系图(Contradiction Entity-Relationship Graph, CERG)。CERG能够把篇章级多模态矛盾扩展到短文级。机器随后扮演导师的角色,提取短文级矛盾作为指导(Guidance)。随后,通过记忆网络来捕捉指导(Guidance)中的信息,通过注意力机制来对多模态输入的全局特征联合推理。
全文中的局部特征很难被汇总出来,尤其是还加入了图像信息的时候。本文发现可以用矛盾语义关系来处理这个问题。矛盾关系意味着两种表述不会同时为真。在长文本中,矛盾关系就容易汇总,因为即使加入了调和性的表述,相反的表达仍然是矛盾的。
. The lower part of the figure is the module of Instructor-Guided Knowledge Extraction (IGKE), which represents facts in the long essays and images with the Contradiction Entity- Relationship Graphs (CERGs). The upper part is the module of Answer Generation by Joint Reasoning (AGJR), which accesses the Guidance under a memory network and consequently generates answers by reasoning over the integrated latent facts accordingly by the attention mechanisms.")
2018 Tips and Tricks for Visual Question Answering Learnings from the 2017 Challenge
Teney D, Anderson P, He X, et al. Tips and tricks for visual question answering: Learnings from the 2017 challenge[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4223-4232.
本文认为研究现状在把VQA模型和流程弄得越来越复杂,各种设计、模块、机制缠在一起,使得这些模型中每一种设计和开发选择到底有多大作用变得难以弄清。这种研究现状把研究方向都带跑偏了,使得开发一个最佳模型不仅仅是科学研究,还成了艺术。
本文详细研究了VQA模型设计中,各种选择(参数、机制、模型结构)到底有什么影响。
本文总结出以下发现:
- 使用sigmoid outputs:能够允许对每个问题的多个正确答案;
- 使用soft scores作为ground truth target:把问题转换为对候选答案的得分回归问题,而不是传统分类;
- 使用gated tanh activations:非线性层的激活函数;
- 使用image features from buttom-up attention:提供特定区域的特征,而不是对传统的从CNN中取得的特征映射图做网格划分;
- 使用pretrained representations of candidate answers:初始化输出层的权重;
- 在随机梯度下降SGD训练中,使用large mini-batches和smart shuffling处理数据。

本文的模型基于深度神经网络实现,对输入问题和图像做联合嵌入,对一组候选答案做多标签分类。
2018 Two can play this Game Visual Dialog with Discriminative Question Generation
Jain U, Lazebnik S, Schwing A G. Two can play this game: visual dialog with discriminative question generation and answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 5754-5763.
本文主要研究自动对话生成。本文给出一个数据集,并提供一个baseline模型,能够预测回答或预测问题。
 to output probabilities of the answer options.")
2018 Visual Question Answering with Memory-Augmented Networks
Ma C, Shen C, Dick A, et al. Visual question answering with memory-augmented networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6975-6984.
本文研究如何用记忆增强神经网络(memory-augmented neural network)来实现准确的VQA模型,甚至是在训练集中的极低频答案,也能预测正确。
记忆神经网络通过结合内部和外部记忆块,选择性地对训练过程中的范例(exemplar)施以注意力。本文发现记忆增强神经网络能够对极其稀有地训练范例维持相对较长的记忆,这种特性能够用于应对VQA场景下“答案”的“长尾”分布问题(少部分答案高频出现,而大量答案的出现概率都很低)。

本文提出的算法流程: 1. 从预训练CNN的最后池化层提取包含空间布局信息的图像特征; 2. 用双向LSTM来生成每个单词的定长特征向量; 3. 协同注意力机制注意相关图像区域及文本单词; 4. 把注意力加权后的图像与问题特征向量连接起来并输入到记忆增强网络中; 5. 在记忆增强网络中,包含一个标准LSTM和一个增强外部记忆;LSTM充当控制器,决定何时读写外部记忆;记忆增强网络维持对罕见训练数据长程记忆。 6. 把记忆增强网络的输出作为对图像和问题对的最终嵌入向量,把该嵌入向量输入到分类器中用于预测答案。
2018 Visual Question Generation as Dual Task of Visual Question Answering
Li Y, Duan N, Zhou B, et al. Visual question generation as dual task of visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6116-6124.
视觉问答VQA和视觉问题生成VQG都是热门方向,但研究现状是两个方向的研究室彼此分离的,但本文认为其实VQA和VQG之间是具备内在互补关系的。
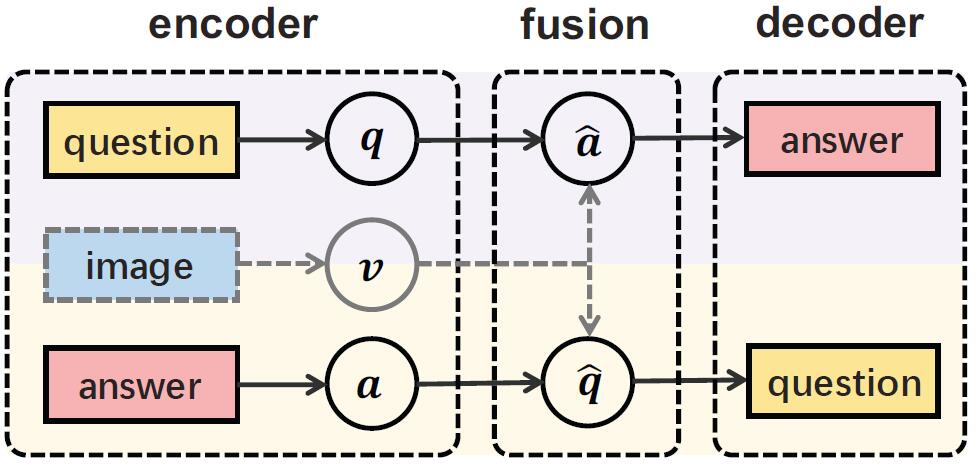
本文提出一款端到端的可反转问答网络(Invertible Question Answering Network, iQAN),iQAN把VQA和VQG视为对偶任务。iQAN模型中,本文提出的可反转双线性融合模块(invertible bilinear fusion module)和参数共享模式(parameter sharing scheme)可以同时实现VQA及对偶任务VQG。训练时,iQAN模型使用本文提出的双正则化器(称为Dual Training)对VQA和VQG任务联合训练。测试时,训练好的iQAN模型在输入answer时就预测输出question,在输入question时就预测输出answer。基于对VQA和VQG的对偶学习,iQAN的模型对图像、问题和回答之间的交互关系理解能力更好。
, which consists two components for VQA and VQG respectively. The upper component is MUTAN VQA component [3], and the lower component is its dual VQG model. Input questions and answers are encoded respectively by an RNN and a lookup table Ea into fixed-length features. With attention and MUTAN fusion module, predicted features are obtained. The predict features are used for obtaining output (by LSTM andWa for questions and answers respectively). A duality and Q duality are duality regularizers to constrain the similarity between the answer and question representations in both models. Two components share the MUTAN and Attention Modules. (·) ∗ denotes the dual form. Ea also shares parameters withWa.")
2018 Visual Question Reasoning on General Dependency Tree
Cao Q, Liang X, Li B, et al. Visual question reasoning on general dependency tree[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 7249-7257.
本文提出名为对抗组合模块网络(Adversarial Modular Network, ACMN)来实现能够在多样且不受限的情况下,有效对齐图像和语言域全局上下文推理。ACMN模型包含两个协同模块:
一个对抗注意力模块(adversarial attention module):提取每一个从问题中解析出的单词的局部视觉依据;
一个残差组合模块(residual composition module):组合已经挖掘出的依据。
给定一个问题的依存解析树,对抗注意力模块通过对抗方式,密集地合并孩子单词节点的区域来逐渐地探索一个单词地显著区域。接着,残差组合模块通过求和池化和残差链接合并任意数量的子节点的隐表示。本文的ACMN模型能够构造一个可解释的VQA系统,能够根据问题驱动的推理路线,逐渐深入发现图像痕迹。ACMN模型通过整合所有注意力模块学习到的知识来实现全局推理。
 that sequentially performs reasoning over a dependency tree parsed from the question. Conditioning on preceding word nodes, our ACMN alternatively mines visual evidence for nodes with modifier relations via an adversarial attention module and integrates features of child nodes of nodes with clausal predicate relation via a residual composition module.")
 each ACMN module that is composed by an adversarial attention module and residual composition module; b) adversarial attention module; c) residual composition module. The blue arrows indicate the modifier relation and the yellow arrows represent the clausal predicate relation. Each node receives the output attention maps and the hidden features from its children, as well as the image feature and word encoding. The adversarial attention module is employed to generate a new attention map conditioned on image feature, word encoding and previous attended regions given by modifier-dependent children. The residual composition module is learned to evolve higher-level representation by integrating features of its children and local visual evidence.")
2018 VizWiz Grand Challenge Answering Visual Questions from Blind People
Gurari D, Li Q, Stangl A J, et al. Vizwiz grand challenge: Answering visual questions from blind people[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 3608-3617.
本文提出VizWiz数据集,首个目标导向(goal-oriented)的VQA数据集。
VizWiz数据集时面向盲人问答的数据集,数据集中的图像和问题由盲人用手机拍摄和记录,每个问题包含10个众包答案。
 and cannot be answered from the image (bottom row).")
2019 Answer Them All! Toward Universal Visual Question Answering Models
Shrestha R, Kafle K, Kanan C. Answer them all! toward universal visual question answering models[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 10472-10481.
VQA的研究现状分两个阵营:
专注于需要现实图像理解的VQA数据集;
专注于检验推理能力的合成数据集。
按理说,一个好的VQA模型要能够在这两种情况下都表现很好,具备良好的泛化能力。但实际上,经过本文的实验对比,所有的方法都无法在领域之间做到泛化。
本文提出一种新的VQA算法,能够匹敌甚至超过这两个领域的最优方法。
.")
本文提出多模态嵌入的循环聚合网络(Recurrent Aggregation of Multimodal Embeddings Network, RAMEN)。
本文的RAMEN模型在概念上架构简单,以便适应复杂的现实场景。RAMEN模型对视觉和问题特征的处理分三阶段: 1. 视觉和语言特征的早期融合(Early fusion of vision and language features):已有研究表明,视觉特征和语言特征的早期融合有助于组合推理。RAMEN模型通过把问题特征与其空间上定位的视觉特征做连接。 2. 通过共享投影学习双模态嵌入(Learning bimodal embeddings via shared projections):视觉+问题的连接特征输入到一个共享网络中,生成空间定位的双模态嵌入。该阶段帮助网络学习视觉与文本特征之间的相互关系。 3. 循环聚合习得的双模态嵌入(Recurrent aggregation of the learned bimodal embeddings):通过双向GRU(bi-GRU)聚合整个场景下的双模态嵌入来捕捉双模态之间的交互。最终的前向和后向状态基本上保留了回答问题所需的所有信息。
2019 Cycle-Consistency for Robust Visual Question Answering
Shah M, Chen X, Rohrbach M, et al. Cycle-consistency for robust visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 6649-6658.
本文任务VQA的研究现状存在对鲁棒性关注不足的问题。
本文给出:
- 新评价协议;
- 相应的新数据集VQA-Rephrasings。 本文的研究表明目前的VQA模型在问题语句的语言变化时难以保持稳定。
VQA-Rephrasing数据集从VQA v2.0发展而来,包含4万个图像,对应的4万个问题通过人工改写成了3个表述方式不同的问题语句。
 Abstract representation of the proposed cycle-consistent training scheme: Given a triplet of image I, question Q, and ground truth answer A, a VQA model is a transformation F : (Q, I) 7→ A′ used to predict the answer A′. Similarly, a VQG model G : (A′, I) 7→ Q′ is used to generate a rephrasing Q′ of Q. The generated rephrasing Q′ is passed through F to obtain A′′ and consistency is enforced between Q and Q′ and between A′ and A′′. Image I is not shown for clarity. (b) Detailed architecture of our visual question generation module G. The predicted answer A′ and image I are embedded to a lower dimension using task specific encoders and the resulting feature maps are summed up with additive noise and fed to an LSTM to generate questions rephrasings Q′.")
引入了生成对抗网络中CycleGAN提出的循环一致性(cycle-consistency)原理:
- 重新生成的问题和答案应与ground-truth保持一致
- 视觉问题生成模块的架构细节
2019 Deep Modular Co-Attention Networks for Visual Question Answering
Yu Z, Yu J, Cui Y, et al. Deep Modular Co-Attention Networks for Visual Question Answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 6281-6290.
协同注意力模型对VQA很重要,要把问题中的关键词和图像中的关键目标联系起来。
本文认为当前成功的协同注意力研究主要基于浅层模型,而深度协同注意力模型鲜有进展。
本文提出深度模块化协同注意力网络(Modular Co-Attention Network, MCAN),MCAN模型由模块协同注意力(Modular Co-Attention, MCA)层在深度上级联组成。每一个MCA层通过两个基本注意力单元组成的模块,对问题和图像的自注意力、图像的问题导向注意力(question-guided-attention)进行联合建模。
. In the Deep Co-attention Learning stage, we have two alternative strategies for deep co-attention learning, namely stacking and encoder decoder.")
密集协同注意力机制(dense co-attention mechanism)建模了任意图像区域与任意问题单词之间的密集交互关系,解决了跨模态交互不足,无法正确理解图像-问题之间关系以回答问题的难题。目前的密集协同注意力机制模型BAN、DCN都能级联增加深度,但这些模型相较于浅层模型或粗糙协同注意力模型MFH却没有明显的提升。本文认为深层协同注意力模型的瓶颈在于,缺乏对每个模态密集自注意的同时建模,例如:问题中单词与单词之间的关系、图像中区域与区域之间的关系。

 and (X) denote the question and image features respectively.")
本文基于Transformer模型,设计了两种通用注意力单元:
自注意力单元(self-attention, SA):建模模态内的密集交互(单词与单词、区域与区域);
导向注意力单元(guided-attention, GA):建模模态间的交互(单词与区域); 模块协同注意力(Modular Co-Attention ,MCA)层则通过组合SA和GA单元实现。MCA层支持深度级联。多个级联的MCA层组成了本文提出的深度MCAN模型。 本文在VQA-v2数据集上开展的实验表明,自注意力和导向注意力在协同注意力学习中具备不错的协同增效作用。
2019 Dynamic Fusion With Intra- and Inter-Modality Attention Flow for Visual Question Answering
Gao P, Jiang Z, You H, et al. Dynamic Fusion With Intra-and Inter-Modality Attention Flow for Visual Question Answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 6639-6648.
学习有效的多模态特征融合特征对VQA至关重要。当前的VQA研究没有在一个框架下对模态间和模态内关系进行联合研究。本文认为对于VQA问题,模态内关系和模态间关系是互补的,而现有的模型却忽视了这一点。比如说,对于图像模态,每一个图像区域不仅应该从对应的单词或短语中获取信息,还应该从相关的图像区域获取信息来推测答案;对于问题模态,可以通过推测其它单词来更好地理解问题。因此,本文为建模模态间和模态内信息流提出了一个统一框架。
本文提出基于模态内和模态间信息流的多模态特征动态融合方法——模态内和模态间注意力流动态融合(Fusion with Intra- and Inter-modality Attention Flow, DFAF)框架实现高效的多模态特征融合,以便准确回答视觉问题。该方法能够在视觉模态和语言模态之间传递二者的动态信息。该方法还能稳定捕捉语言域与视觉域之间的高层交互,从而大幅提高VQA能力。本文提出的以其它模态为条件的动态模态内注意力流能够动态调整目标模态的模态内注意力,对多模态特征融合有重要意义。
 for visual question answering. Each DFAF module contains one Inter-Modality Attention Flow and one of Intra Modality Attention Flow Module. Stacking several blocks of DFAF can help the network gradually focus on important image regions , question words and the latent alignments.")
- 堆叠若干个DFAF块可以帮助模型逐渐关注到重要的图像区域、问题单词和隐含对齐关系。

- 动态模态内注意力流(Dynamic Intra-Modality Attention Flow)模块;
- 对问题特征平均池化出的条件门控向量(conditional gating vector)可以控制区域特征之间流动的信息。,这样一来,注意力机制就会关注于与问题相关的信息流。
2019 Explicit Bias Discovery in Visual Question Answering Models
Manjunatha V, Saini N, Davis L S. Explicit Bias Discovery in Visual Question Answering Models[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 9562-9571.
现有的VQA模型过于学习了数据中的统计偏差(statistical biases)。根据数据中的统计规律来回答,而非依据视觉内容。
本文通过简单的规则挖掘(rule mining)算法,发现了一些人类可解释规则,能够给我们对模型的这种行为带来独特的视角。
, and a third which can be answered using statistical biases in the data itself. On the right, we show examples of statistical biases for a set of questions containing the phrase “What time?” and various visual elements (antecedents). Note that each row in this figure represents multiple questions in the VQA validation set. The * next to the answer (or consequent) reminds us that it is from the set of answer words. There are several visual words associated with afternoon and night, but we have provided only two for brevity.")
- 论文图中的单词拼错了,应该是antecedent;
- VQA数据集的VQA样本示例,表格中展示了统计偏差对回答的影响。
2019 Generating Question Relevant Captions to Aid Visual Question Answering
JialinWu, Zeyuan Hu, Raymond J. Mooney. Generating Question Relevant Captions to Aid Visual Question Answering[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 3585–3594.
本文认为VQA和图像描述研究是相通的,实际上都需要连接语言和视觉的通用知识。基于这样的理解,本文提出在做VQA的同时,联合生成能够对回答视觉问题有帮助的描述,由此提升VQA水平。
 and yellow arrows denote attention embedding.")
模型分两阶段训练: 1. 阶段1,模型学习生成问题相关的图像描述。 2. 阶段2,用阶段1生成的问题相关描述来fine-tune VQA模型,并预测输出回答。
2019 Improving Visual Question Answering by Referring to Generated Paragraph Captions
Hyounghun Kim, Mohit Bansal. Improving Visual Question Answering by Referring to Generated Paragraph Captions[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 3606-3612.
本文认为段落风格的图像描述(paragraph-style image caption)比单句描述给出的信息更多。单句描述只是对图像做一个笼统描述,而段落描述则能够描述图像中的不同方面的信息、更抽象的信息、更易于理解的信息、符号表示型的信息,这些信息能够和图像本身所能表达的语义进行互补。

本文提出视觉和文本问答(Visual and Textual Question Answering, VTQA)模型。该模型基于图像及其段落描述,给定问题,输出回答。
本文的段落描述模块基于的Melas-Kyriazi等人2018年的研究,使用CIDEr作为reward实现强化学习。
早期融合(Early Fusion):该阶段把视觉特征(Visual Feature)和段落描述(Paragraph Caption)与目标属性(Object Properties)特征进行融合。
晚期融合(Late Fusion):该阶段把各模块输出的逻辑值整合到一个向量中。
2019 Information Maximizing Visual Question Generation
Krishna R, Bernstein M, Fei-Fei L. Information Maximizing Visual Question Generation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 2008-2018.
本文主要研究视觉问题生成。 本文构建了一个模型,能够最大化图像、预期答案及生成问题之间的互信息。(要生成“好问题”,即与图像内容、预期回答密切相关的问题,而不是非常通用、宽泛的问题,如“图中有什么东西?”)
自然语言tokens是离散分布的,不可微分,为此本文通过变分连续隐空间来映射预期答案。本文通过一个第二隐空间来正则化这个隐空间,由此确保相似答案能够产生聚类。即使我们不知道预期答案时,第二隐空间也能生成一个目标驱动的问题来提取目标。
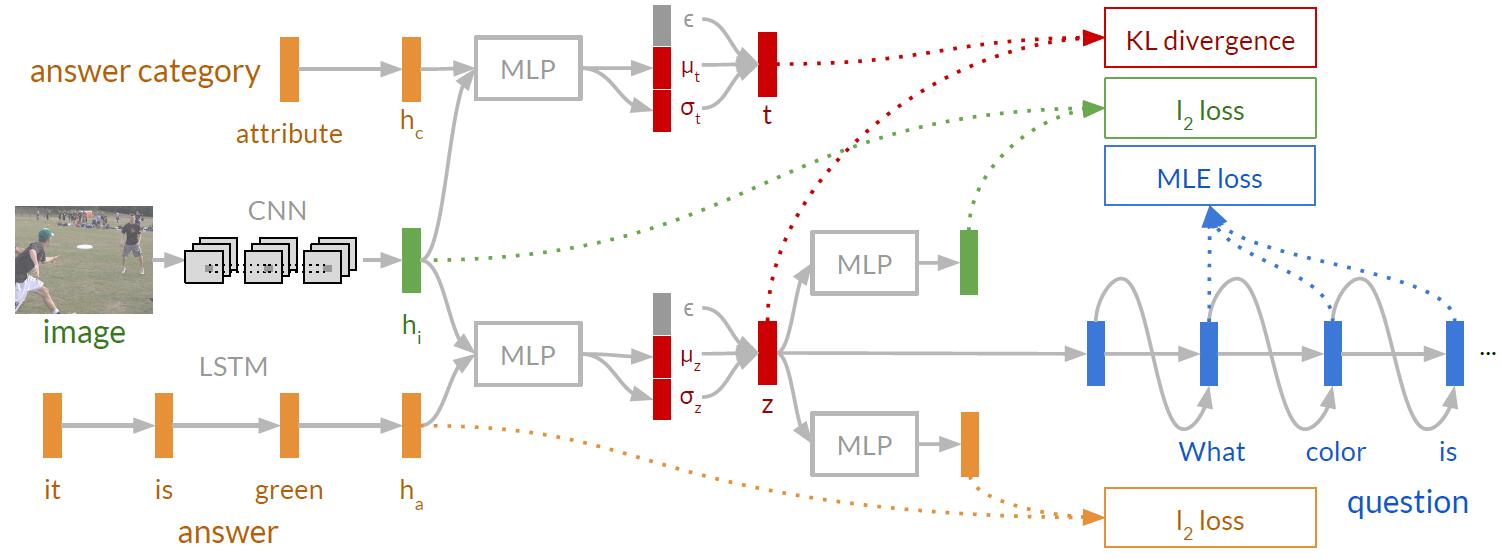
- 模型的训练过程
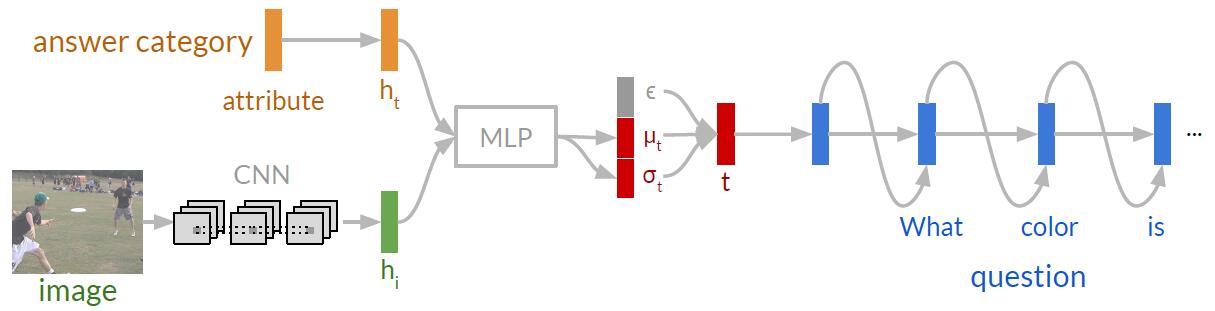
- 模型的测试/推理过程
2019 Multi-grained Attention with Object-level Grounding for Visual Question Answering
Pingping Huang, Jianhui Huang, Yuqing Guo, Min Qiao, Yong Zhu. Multi-grained Attention with Object-level Grounding for Visual Question Answering[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 3595–3600.
本文认为已有研究大多从句子和突破之间的粗粒度关联来训练注意力模型,在小目标或不常见概念上表现很差。
为了更好应对小目标或不常见概念的问题,本文提出一种多粒度注意力模型。通过两种类型的词级注意力来补充句-图关系,该模型能够学习单词-目标之间的显性对应关系。
主流的VQA系统就是通过深度神经网络实现端到端训练。把问题和图片分别编码为表示向量,然后把多模态特征融合为统一表示,来预测回答。找出与问题最相关的图像区域很重要!目前主要的方法是通过注意力机制。通过空间注意力分布(spatial attention distribution)来体现视觉上关注的位置。

- Word-Label Attention
- Word-Object Attention
- Sentence-Object Attention
- 把WL, WO, SO三种注意力权重加起来,取得Object features的多粒度注意力权重结果,用这个多粒度注意力去加权平均object features取得attended object feature向量,作为视觉信息表示。最终与Sentence embedding组合为融合特征,用作VQA答案分类。
2019 MUREL Multimodal Relational Reasoning for Visual Question Answering
Cadene R, Ben-Younes H, Cord M, et al. Murel: Multimodal relational reasoning for visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 1989-1998.
现有的VQA模型主要基于多模态注意力网络。注意力机制可以关注于与问题相关的视觉内容,但注意力机制总的来讲还是比较简单,不具备推理能力,不足以回答复杂的问题。
本文提出MuRel模型,一种多模态关系网络,能够端到端学习在真实图像上进行推理。
- MuRel cell:一个原子化的推理基元,能够通过一个富向量表示来表示问题和图像区域之间的交互,通过成对结合建模区域之间的关系。
- MulRel network:逐步修正视觉和问题交互,比仅使用注意力映射图可以更好定义可视化模式。

- MuRel cell
- MuRel单元中:双线性融合可以表示问题向量\(q\)和区域向量\(s_i\)之间的丰富、细粒度的交互。多模态向量\(m_i\)通过成对关系建模(Pairwise Relational Modeling)块为每个区域生成一个上下文感知嵌入\(x_i\)。对\(x_i\)和\(s_i\)求和获取\(\hat{s}_i\),此处\(s_i\)相当于恒等映射的shortcut,计算过程形成了残差函数。
MuRel cell的输入是问题向量\(q\)和\(N\)个视觉特征\(s_i \in \mathbb{R}^{d_v}\)(还有对应的bounding box坐标信息\(b_i\))。
- 一个高效的双线性融合模块会把问题特征向量和区域特征向量做融合,取得\(N\)个区域的局部多模态嵌入(local multimodal embedding);
- 一个成对关系建模(Pairwise Relational Modeling)组件会根据每个融合过的区域特征向量\(m_i\)的空间和视觉上下文,来更新\(m_i\)为\(x_i\)。
.")
2019 OK-VQA A Visual Question Answering Benchmark Requiring External Knowledge
Marino K, Rastegari M, Farhadi A, et al. OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 3195-3204.
目前的VQA评价指标主要关注简单的,如:计数、视觉属性、目标检测等不需要推理或外部知识的问题。
本文提出一种新的评价指标OK-VQA。在OK-VQA中,图像内容不足以回答问题,因此需要让VQA模型能够集合外部知识资源。
本文致力于基于知识的VQA并为此提出一种新的评价指标OK-VQA。在OK-VQA中,图像内容不足以回答问题,因此需要让VQA模型能够集合外部知识资源。本文的新数据集包含1万4千条需要外部知识回答的问题。

OK-VQA数据集的问题包含对所需外部知识分类的标注,把需要用到的外部知识疯了10类,例如:车辆与交通;品牌、公司和产品;……。
2019 Psycholinguistics Meets Continual Learning Measuring Catastrophic Forgetting in Visual Question Answering
Claudio Greco, Barbara Plank, Raquel Fernández, Raffaella Bernardi. Psycholinguistics Meets Continual Learning Measuring Catastrophic Forgetting in Visual Question Answering[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 3601-3605.
心理语言学遇到持续学习(Psycholinguistics Meets Continual Learning)?

本文具体是评估和分析了VQA中存在的剧烈遗忘(dramatic forgetting)或突变遗忘(catastrophic forgetting)问题。
2019 Textbook Question Answering with Multi-modal Context Graph Understanding and Self-supervised Open-set Comprehension
Daesik Kim, Seonhoon Kim, Nojun Kwak. Textbook Question Answering with Multi-modal Context Graph Understanding and Self-supervised Open-set Comprehension[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 3568-3584.
本文主要关注TQA的两大问题: 1. 多模态上下文的理解。本文提出f-GCN模型,基于GCN,能够从文本和图像中建立上下文图,有助于从长课程中提取和整合知识特征。 2. 科学术语的分布(训练集中有,测试集中无)。本文将其视为out-of-domain问题,通过对无标注的开放数据集的自监督学习来处理。
 The preparation step for the k-th answer among n candidates. The context m is determined by TF-IDF score with the question and the k-th answer. Then, the context m is converted to a context graph m. The question and the k-th answer are also embedded by GloVe and character embedding. This step is repeated for n candidates. (b) The embedding step uses RNNC as a sequence embedding module and f-GCN as a graph embedding module.With attention methods, we can obtain combined features. After concatenation, RNNS and the fully connected module predict final distribution in the solving step.")
从数据模态角度来看,TQA最为复杂,上下文部分和问题部分需要处理的数据都是Text+Image的多模态数据。
本文利用UDPnet来抽取课本的图表中的知识信息。
2019 Transfer Learning via Unsupervised Task Discovery for Visual Question Answering
Noh H, Kim T, Mun J, et al. Transfer Learning via Unsupervised Task Discovery for Visual Question Answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 8385-8394.
本文研究如何用现有的视觉数据、语言数据来应对VQA中回答在答案词汇以外的情况。
2019 Visual Question Answering as Reading Comprehension
Li H, Wang P, Shen C, et al. Visual Question Answering as Reading Comprehension[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 6319-6328.
本文认为与其纠结怎么弄多模态特征融合,不让干脆把图像信息转成自然语言文本,这样视觉问答就变成文本问答问题了。
把VQA转换为全文本处理后,还有助于处理基于知识的VQA,因为基于知识的VQA本身需要挖掘大规模的外部知识库。

- VQA与TQA对比